Expand beyond technology
Generative AI & Machine Learning Program for Tech Professionals
In Collaboration With
Free Career Counselling
IBM
Certified Capstone
175%
Average Salary Hike
35K+
Trusted Learners


Job Roles You Can Target
Sr. ML Engineer : 33 LPA
Sr. AI Engineer : 20.9 LPA
NLP Engineer : 13 LPA
Dedicated Job Assistance
Mastering the Future: Advanced AI & ML

Gain cutting-edge skills in AI and Machine Learning
Expert crafted curriculum that readies you for advanced AI ML job roles

Maximize Your Earning Potential
Gain skills and earn higher salaries in the booming AI & ML industry

Curriculum inclusive of Gen-AI
Tailored for career transformation in a tech-driven era

Why choose Learnbay?

Training mode
You can choose from two flexible training modes to suit your needs and preferences:
.webp&w=128&q=75)
100% Live online classes
.webp&w=128&q=75)
Hybrid * projects

Specialize in your Domain
Choose from BFSI, Retail, Healthcare, and more for focused, relevant learning.
Manufacturing
Technology
Consulting
Healthcare
BFSI
Retail
.webp&w=256&q=100)
Real Projects, Real Experience
Master data science & AI by working on 100+ real-world projects with expert guidance.
Get project Certification from:
Renowened Industry
.webp&w=256&q=100)
Reach your career goals
Advance your career with our effective Placement Support.






Real Stories, Real Success
Discover what our learners say about us






9K+
Successful Career Transitions
175%
Average Salary Hike
Courses Top Rated in:
Discover what our learners say about us





Hear it from Alumni

Alumni Spotlight

Who is this program for
Education
Bachelor's degree with consistent good academic
Work Exp.
Minimum 1 year of IT/Non-IT work experience
Career Stage
Early to mid-career professionals interested in AI & ML
Aspirations
Developing skills in AI & ML for future opportunities
Learnbay’s ProjectLab
Project Innovation Lab
Project Certification
Domain Specialization

35K+
Mentors help you select the domain & guide you through.
Key Benefits
Work in an industry like environment and gain practical hands-on experience
Gain the work experience of data scientist with dedicated project mentors from industry.
Land Your Dream Job with Career Services PRO
1:1 Doubt Sessions
Interview Prep.
Resume BuildUp
3 Years Flexible Sub.

GetHired At


Can’t decide which program to opt for?
Don’t worry, our expert counsellor is there to guide you make the right career choice

Learning journey at Learnbay




Upskill Now
Live sessions, expert 1:1 doubt clearing, and quizzes.Capstone Projects
Work with industry experts on practical projects.Boost Profile
Mock interviews and resume-building sessionsCareer Goals
Get placement assistance with top companies.Explore our Syllabus
Curriculum is specifically engineered to meet the expectations of leading tech companies

Module 0 :- Python Bootcamp for Non-Programmers
Topic 1 :- Installation & Setup
Topic 2 :- Basic Syntax & I/O
Topic 3 :- Control Structures
Topic 4 :- Basic Data Structures


TERM 1 :- Python for Data Science

TERM 2 :- Statistics and Machine Learning

TERM 3 :- Generative AI and Agentic AI

TERM 4 :- Data Visualization & Data Analysis

TERM 5 :- AI Tools and Deployment
Programming Languages & Tools Covered


Industry Recognized Certification Course
Course Completion Certificate from IBM
Complete your training with the internationally recognized certificate.
Validate your Data Science and AI skills with IBM Course Completion Certificate.
Get acknowledged in IT sector by adding IBM Certificate to your profile.

Fee & Batch Details
Live online classes
Benefits :
- Live online interactive sessions
- 1:1 online Doubt Session with experts
- Online Capstone projects
- Virtual Mock interviews
Program Fee:
₹ 1,59,000 + 18% GST
No Cost EMI Available
Meet Our Mentors
Guiding You Every Step of the Way Towards Professional Excellence
Disha Jindgar

Disha M.

Tammanna V.

Mohit S.

Pulkit Jain

Tripti Jain

Ankur K.
Get job ready within 6 months with Career Services
Placement Support
Placement Support
Unleash your career potential with interview support and profile review.
Receive 8-10 interview calls from a diverse pool of interested employers/recruiters until you successfully secure a job.
Find the best suited job role that meets your career and salary expectations.

Mock Interviews
Resume BuildUp
8-10 Interview Calls
Placement Support
Unleash your career potential with interview support and profile review.
Receive 8-10 interview calls from a diverse pool of interested employers/recruiters until you successfully secure a job.
Find the best suited job role that meets your career and salary expectations.
Dedicated Placement Cell
Job roles & companies you can target
Sr. Data Scientist
ML Engineer
AI Engineer
BI Engineer
BI Developer
Sr. Data Analyst
Business Analyst
DataBase Admin





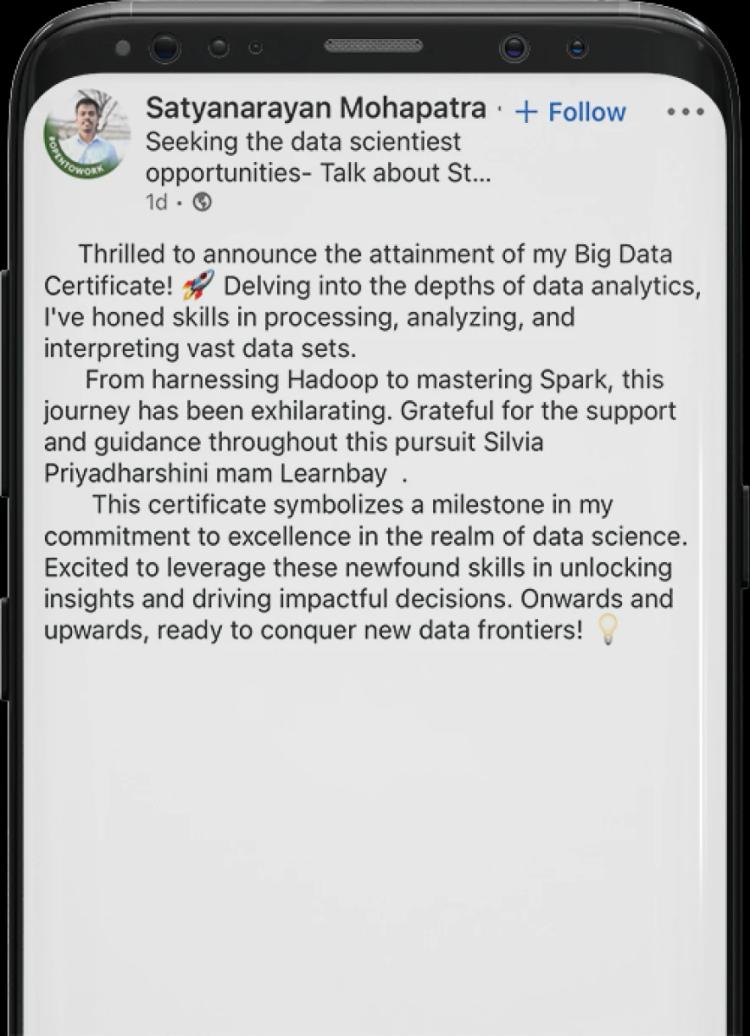
Insider glimpses: Click to see real conversations with our learners







Industry Projects
Curriculum is specifically engineered to meet the expectations of leading tech companies.
-min.png&w=640&q=75)
Learn and develop classification techniques for the digital transformation of banking
JPMorgan offers tax-friendly insurance choices. You can help them forecastinsurance premiums. Targeted marketing using your random forest algorithm skills can help obtain better premium values.


Building a content recommendation model on the basis of regional viewer categorization
Netflix is a global entertainment video streaming site. They offer content in various regional languages. Build a local recommendation engine for Netflix customers residing in south Bangalore on their weekend and weekdays activities, utilizing NLP.


Understanding in-depth about logging while drilling (LWD) technique
Saudi Aramco company is working onthe development of high-efficiency drilling models. Use the bright sides of big data analytics to identify the most cost-effective and highly productive drilling sites.


Career progression planning of employees with workforce defections & efficiency
IBM intends to boost its HR department by identifying employees' masked inconsistency. They need models to identify the graphical variations in their 14000+ employees' performances. Help them build models with your regressions and other ML abilities.

FAQs
Curriculum is specifically engineered to meet the expectations of leading tech companies.
What are the prerequisites for the AI & ML Program?
What if I miss a few classes due to an emergency?
In case you miss a few classes, you will be provided with backup classes in other batches. But if you could not attend more classes, you can opt for batch change and join the next batch.
What is a Flexi Subscription in the AI & ML Program?
Those who enroll for Data Science live classroom training are eligible for a Flexi Pass. With this option, we will share access to all the ongoing batch details for a period of 2 years, so that you can attend live sessions from any batch and learn at your own pace. This option is best for people working in shifts or on weekends.
What’s the duration of the AI & ML Program?
The duration of this course is about 9 months (275 hours) which includes live lectures, hands-on practical training on live projects, and interview preparations. Classes will be conducted on weekdays and weekend batches. Weekday batch – 7 months, Monday to Friday – 2 hours/day, Weekend batch – 9 months, Saturday & Sunday – 3.5 hours/day
What is the mode of training at Learnbay?
We provide both classroom and online data science training modes. Based on your requirement, you can choose your preferred mode.
How can I opt for a Hybrid mode of learning?
Simply, you can choose an online mode of study for the theoretical classes and classroom mode for all the capstone projects and interview preparation sessions.
What are the prerequisites for the AI & ML Program?
What if I miss a few classes due to an emergency?
In case you miss a few classes, you will be provided with backup classes in other batches. But if you could not attend more classes, you can opt for batch change and join the next batch.
What is a Flexi Subscription in the AI & ML Program?
Those who enroll for Data Science live classroom training are eligible for a Flexi Pass. With this option, we will share access to all the ongoing batch details for a period of 2 years, so that you can attend live sessions from any batch and learn at your own pace. This option is best for people working in shifts or on weekends.
What’s the duration of the AI & ML Program?
The duration of this course is about 9 months (275 hours) which includes live lectures, hands-on practical training on live projects, and interview preparations. Classes will be conducted on weekdays and weekend batches. Weekday batch – 7 months, Monday to Friday – 2 hours/day, Weekend batch – 9 months, Saturday & Sunday – 3.5 hours/day
What is the mode of training at Learnbay?
We provide both classroom and online data science training modes. Based on your requirement, you can choose your preferred mode.
How can I opt for a Hybrid mode of learning?
Simply, you can choose an online mode of study for the theoretical classes and classroom mode for all the capstone projects and interview preparation sessions.
Gain Expertise to Grow Beyond Technology with Artificial Intelligence Certification Program
Leap forward with the Artificial Intelligence Certification Program to unleash a data-driven future globally. Register with Learnbay’s ‘Advance AI & ML Certification Program for Tech Professionals’ today. This program intends to bridge the learning gaps for tech experts and help them land attractive job prospects.
Read More...
24X7 Learner’s Support

