India’s #1
Tech-Upskilling Platform for Working Professionals
Curriculum inclusive of GenAI and ChatGPT
Data Science & AI
Cloud & DevOps
Master’s Degree

Data Science & AI
Cloud & DevOps
Master’s Degree Program

Learn from Top 1% Tech Mentors


Domain Certification Courses



Our Certification Courses











Why choose Learnbay for Upskilling?
We have upskilled thousands of professionals from various domains to land their dream tech job.
250% Avg.
Salary Hike
Dedicated
Placement Cell
Live online
Interactive Session


Work on Real Project with Learnbay’s ProjectLab

Project Innovation Lab
Work in an industry like environment and gain practical hands-on experience
Gain the work experience of data scientist with dedicated project mentors from industry.
Build project portfolio with domain specific capstone projects

Project Certification from IBM
Gain real proof of hands-on experience by having your project certified by the industry
Make your past experiences count with domain specialisation and Project certification







Real Stories, Real Success
Discover what our learners say about us






9K+
Successful Career Transitions
175%
Average Salary Hike
Courses Top Rated in:
Discover what our learners say about us





Hear it from Alumni

Alumni Spotlight

Get Ahead with Industry-Leading Courses
“
I had a great learning experience at Learnbay. The faculties here are top notch. Right from enrollment to getting a good job, they keep putting enormous efforts for each and every candidate. Thanks to all the trainers, backend team, the HR team and to the directors for making this journey smooth.

Preksha Mishra
Working at HCL
Apply for Career Counselling
Land Your Dream Job with Career Services PRO
1:1 Doubt Sessions
Interview Prep.
Resume BuildUp
3 Years Flexible Sub.

GetHired At


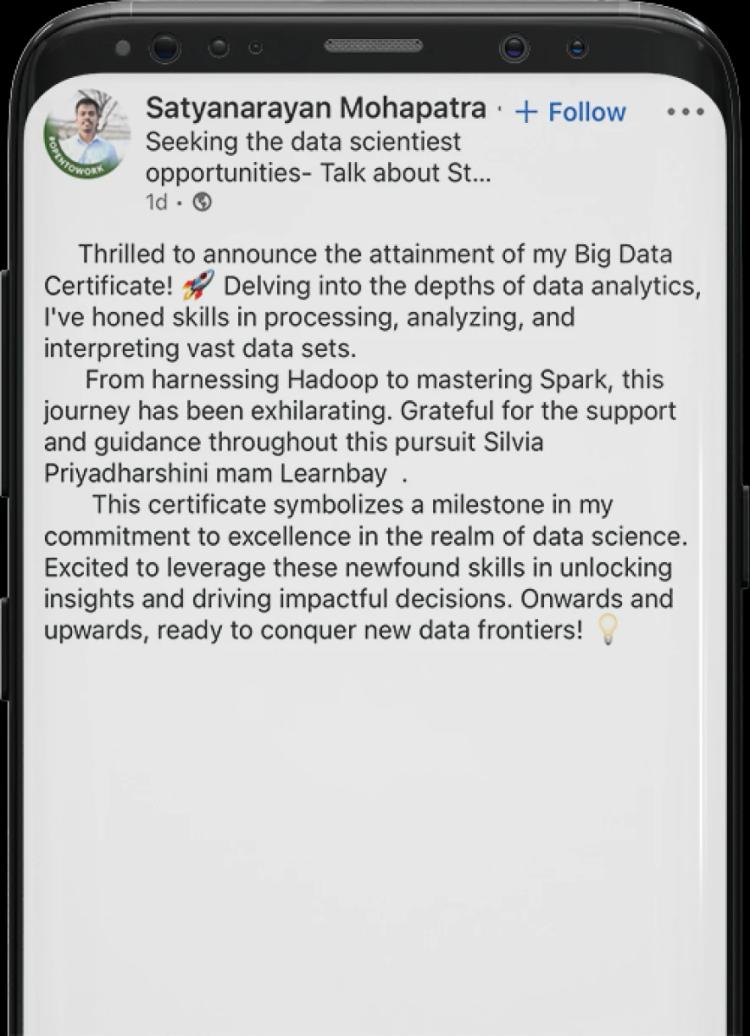
Insider glimpses: Click to see real conversations with our learners







Featured in
Media Spotlight
24X7 Learner’s Support

